关于文档的基本操作(重点):
基本操作:
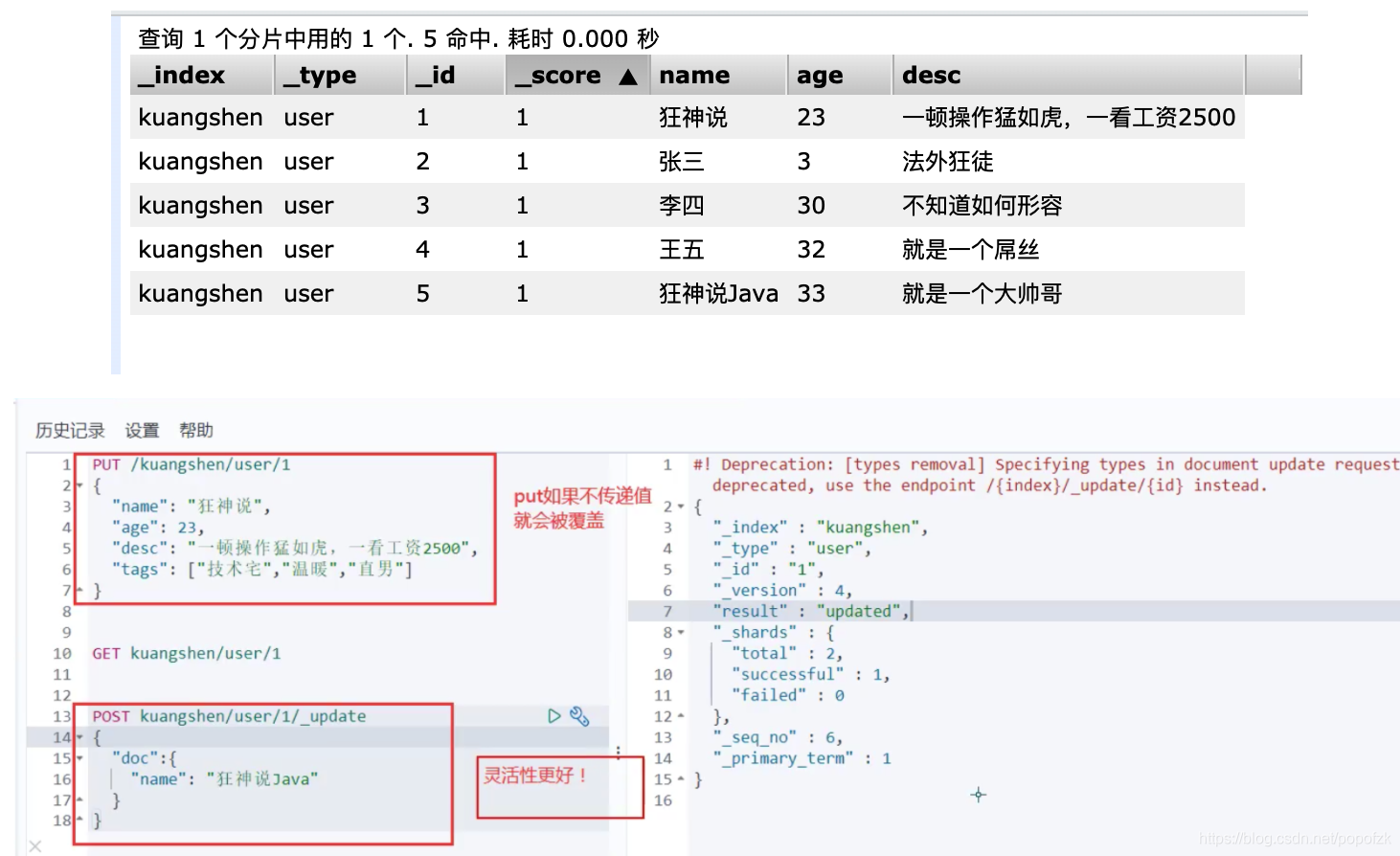
添加数据


更新数据,将小明改成小红

PUT更新数据

version代表被改变的次数
Post,_update自由度更高,PUT必须一次性修改一个个体的全部内容,但是Post可以选择部分修改!

这个和PUT无异,要在后加_update

简单的搜索:
1
| GET Kuangshen/user/_search?q=name:狂神说
|

简单的条件查询,可以根据默认的映射规则,产生基本的查询!

复杂操作搜索 select(排序,分页,高亮,模糊查询,精准查询)
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| {
"took" : 0,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 5,
"relation" : "eq"
},
"max_score" : 1.0,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.0,
"_source" : {
"name" : "狂神说",
"age" : 23,
"desc" : "一顿操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "2",
"_score" : 1.0,
"_source" : {
"name" : "张三",
"age" : 3,
"desc" : "法外狂徒",
"tags" : [
"交友",
"旅游",
"渣男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "3",
"_score" : 1.0,
"_source" : {
"name" : "李四",
"age" : 30,
"desc" : "不知道如何形容",
"tags" : [
"篮球",
"IT",
"型男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "4",
"_score" : 1.0,
"_source" : {
"name" : "王五",
"age" : 32,
"desc" : "就是一个屌丝",
"tags" : [
"羽毛球",
"钢琴",
"渣男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "5",
"_score" : 1.0,
"_source" : {
"name" : "狂神说Java8",
"age" : 34,
"desc" : "就是一个大帅哥",
"tags" : [
"围棋",
"小提琴",
"暖男"
]
}
}
]
}
}
|
1
2
3
4
5
6
7
8
| GET kuangshen/_search
{
"query": {
"match": {
"name": "狂神"
}
}
}
|
输出:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
| {
"took" : 9,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 2,
"relation" : "eq"
},
"max_score" : 1.9034984,
"hits" : [
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "1",
"_score" : 1.9034984,
"_source" : {
"name" : "狂神说",
"age" : 23,
"desc" : "一顿操作猛如虎,一看工资2500",
"tags" : [
"技术宅",
"温暖",
"直男"
]
}
},
{
"_index" : "kuangshen",
"_type" : "user",
"_id" : "5",
"_score" : 1.6534033,
"_source" : {
"name" : "狂神说Java8",
"age" : 34,
"desc" : "就是一个大帅哥",
"tags" : [
"围棋",
"小提琴",
"暖男"
]
}
}
]
}
}
|
hit: 索引和文档信息
查询的结果总数
然后就是查询出来的具体文档
数据中的东西都可以遍历出来
分数:通过score判断谁更加符合结果
指定字段查询:
1
2
3
4
5
6
7
8
9
| GET kuangshen/_search
{
"query": {
"match": {
"name": "狂神"
}
},
"_source": ["name","desc"]
}
|
之后使用java操作es,所有的方法和对象就是这里面的key!
复杂操作:
排序
order中的desc降序、asc升序;按照age
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| GET kuangshen/_search
{
"query": {
"match": {
"name": "狂神"
}
}
,"sort": [
{
"age": {
"order": "desc"
}
}
]
}
|
分页
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
| GET kuangshen/_search
{
"query": {
"match": {
"name": "狂神"
}
}
,"sort": [
{
"age": {
"order": "desc"
}
}
],
"from": 0,
"size": 1
}
|
From:从第几个数据开始,返回多少条数据(单页面的数据)
数据下标还是从0开始的,和学的所有数据结构是一样的
/search/{current}/{pagesize}
布尔值查询
通过布尔值进行更加精确的查询:多条件精确查询
must命令(相当于mysql的and),即所有条件要同时符合;如果将must改为should(相当于or),则只要满足其一即可;
类似的 must not 查询不是。。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神说"
}
},
{
"match": {
"age": 23
}
}
]
}
}
}
|
过滤器(filter)
筛选age范围
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| GET kuangshen/user/_search
{
"query": {
"bool": {
"must": [
{
"match": {
"name": "狂神"
}
}
],
"filter": [
{
"range": {
"age": {
"gte": 10,
"lte": 40
}
}
}
]
}
}
}
|
- gt 大于
- gte 大于等于
- lt 小于
- lte 小于等于
匹配多个条件
匹配出tags里面只要包含有男的,同时按照上到下分值高到低排列
1
2
3
4
5
6
7
8
| GET kuangshen/user/_search
{
"query": {
"match": {
"tags": "男 技术"
}
}
}
|

多个条件使用空格隔开
只要满足其中一个结果即可以被查出
这个时候可以通过分值基本的判断
精确查询
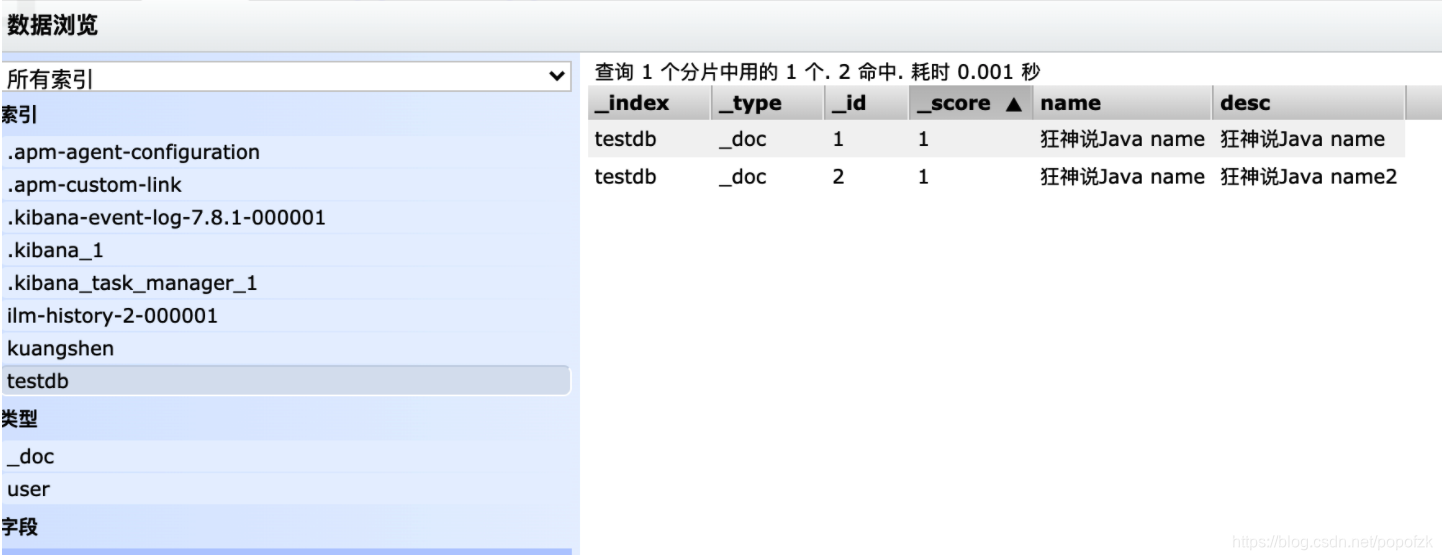
term查询是直接通过待排索引指定的词条进行精确的查找的!
关于分词:
term,直接查询精确的
match:会使用分词器解析!(先分析文档,然后再通过分析的文档进行查询!)
两个字段类型text keyword
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| #新建db
PUT testdb
{
"mappings": {
"properties": {
"name":{
"type": "text"
},
"desc":{
"type": "keyword"
}
}
}
}
#插入两条数据
PUT testdb/_doc/1
{
"name": "狂神说Java name",
"desc": "狂神说Java name"
}
PUT testdb/_doc/2
{
"name": "狂神说Java name",
"desc": "狂神说Java name2"
}
|
1
2
3
4
5
6
7
8
9
10
11
| GET _analyze
{
"analyzer": "keyword",
"text": "狂神说Java name"
}
GET _analyze
{
"analyzer": "standard",
"text": "狂神说Java name"
}
|

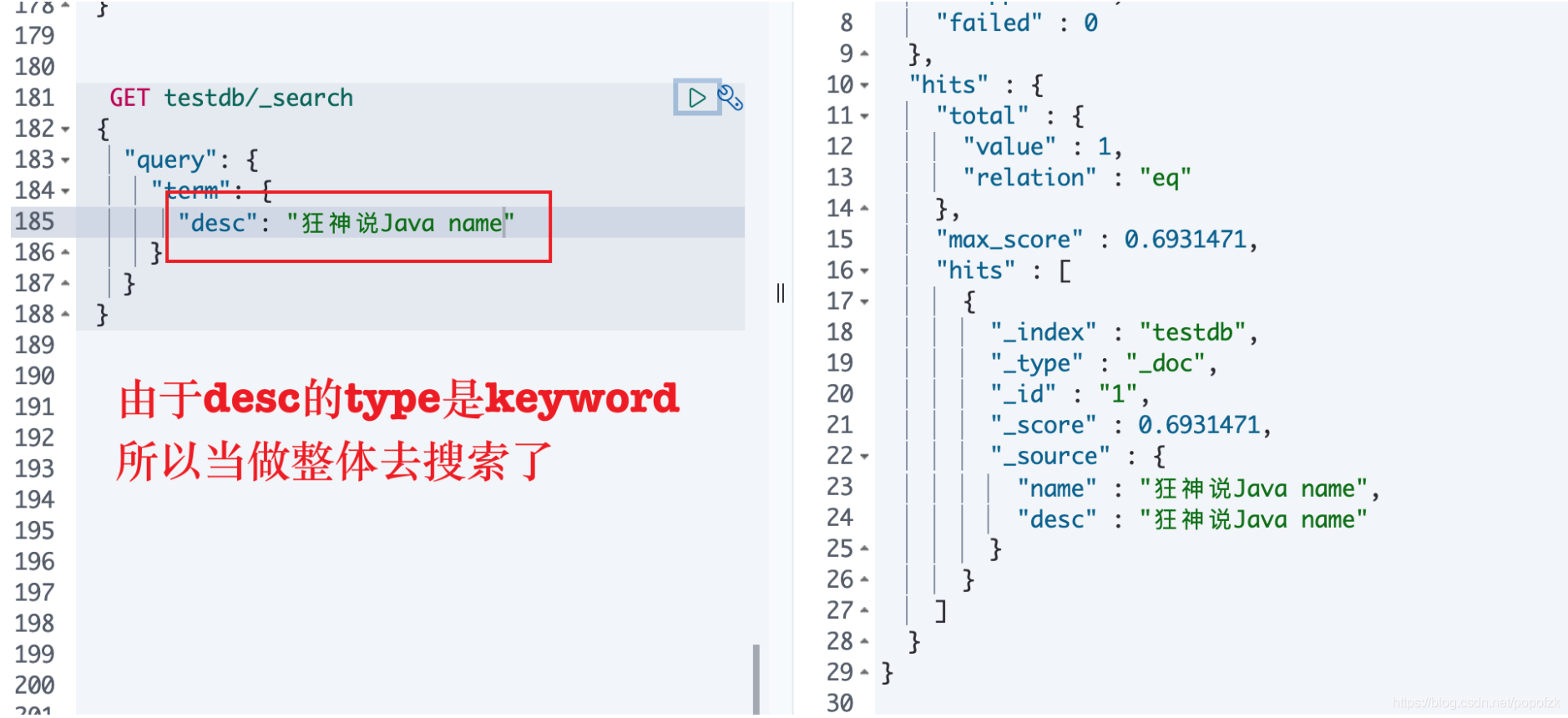
由于desc的type是keyword,当做整体去搜索了
总结:keyword字段类型不会被分词器解析!
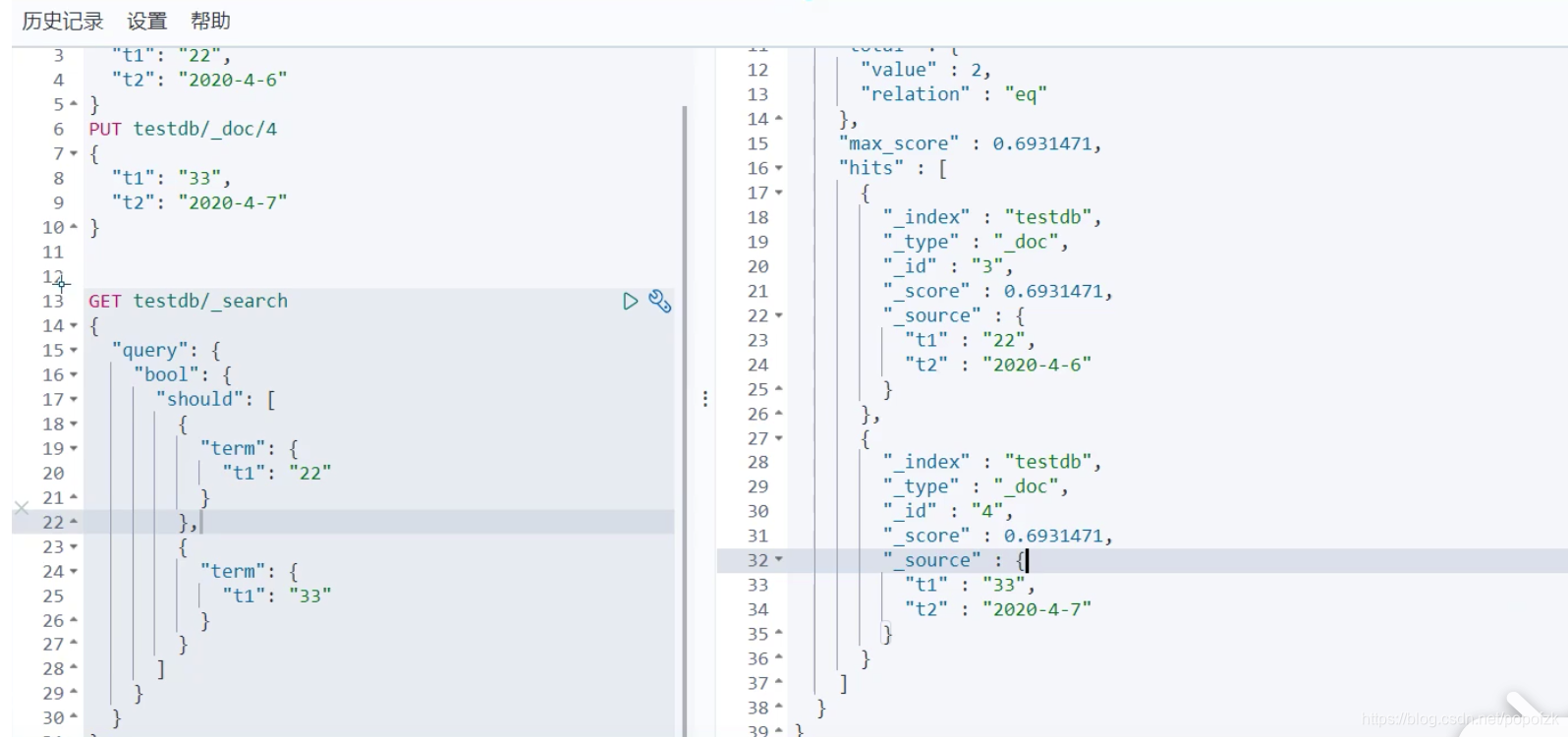
多个值匹配的精确查询
精确查询多个值
高亮查询
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| GET kuangshen/user/_search
{
"query": {
"match": {
"name": "狂神说"
}
},
"highlight": {
"pre_tags": "<p class='key' style='color:red'>",
"post_tags": "</p>",
"fields": {
"name": {}
}
}
}
|
默认是<em>标签

也可以是自定义标签:设置pre_tags、post_tags

- 匹配
- 按照条件匹配
- 精确匹配
- 区间范围匹配
- 匹配字段过滤
- 多条件查询
- 高亮查询
集成Springboot
文档
https://www.elastic.co/guide/index.html
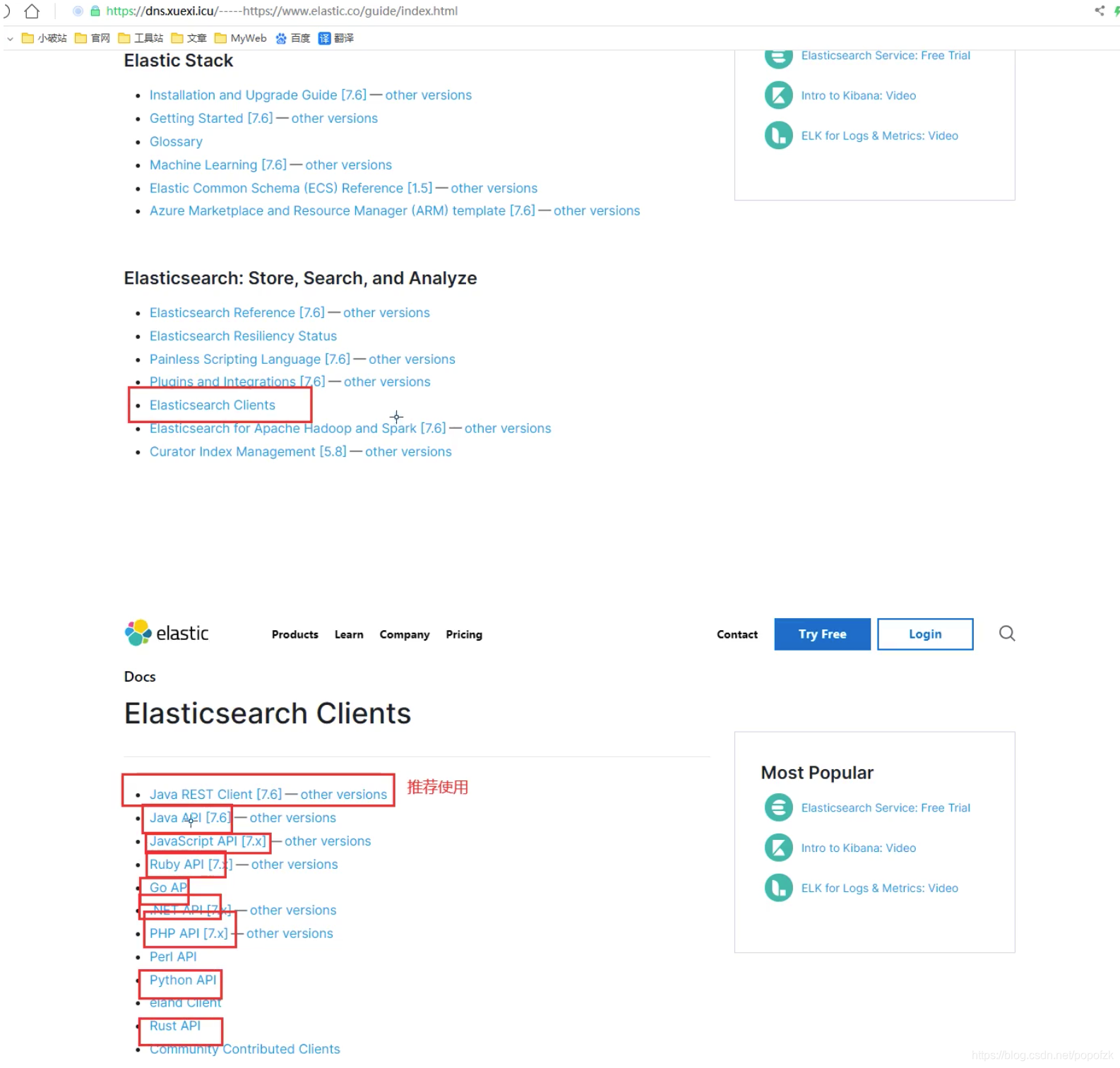
找原生依赖

初始化

配置
新建一个empty project ,再创建普通模块

创建Springboot 模块:

勾上依赖:

由于刚刚建的空project,故要陪JDK环境




问题:一定要保证我们的导入依赖和我们的es版本一致
默认的导入依赖和我们本地的版本不一致!
可以自定义版本依赖,保证一致
新建config、ElasticSearchConfig.java`
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| package com.kuang.config;
import org.apache.http.HttpHost;
import org.elasticsearch.client.RestClient;
import org.elasticsearch.client.RestHighLevelClient;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class ElasticSearchConfig {
@Bean
public RestHighLevelClient restHighLevelClient(){
RestHighLevelClient client = new RestHighLevelClient(
RestClient.builder(
new HttpHost("localhost", 9200, "http"),
new HttpHost("localhost", 9201, "http")));
return client;
}
}
|
源码

具体测试es api:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
| package com.kuang;
import org.elasticsearch.client.RequestOptions;
import org.elasticsearch.client.RestHighLevelClient;
import org.elasticsearch.client.indices.CreateIndexRequest;
import org.elasticsearch.client.indices.CreateIndexResponse;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.boot.test.context.SpringBootTest;
import java.io.IOException;
@SpringBootTest
class KuangshenEsApiApplicationTests {
@Autowired
@Qualifier("restHighLevelClient")
private RestHighLevelClient client;
@Test
void testCreateIndex() throws IOException {
CreateIndexRequest request = new CreateIndexRequest("kuang_index");
CreateIndexResponse createIndexResponse =
client.indices().create(request, RequestOptions.DEFAULT);
System.out.println(createIndexResponse);
}
@Test
void testExistIndex() throws IOException {
GetIndexRequest request = new GetIndexRequest("kuang_index");
boolean exists = client.indices().exists(request, RequestOptions.DEFAULT);
System.out.println(exists);
}
@Test
void testDeleteIndex() throws IOException {
DeleteIndexRequest request = new DeleteIndexRequest("testdb2");
AcknowledgedResponse delete = client.indices().delete(request, RequestOptions.DEFAULT);
System.out.println(delete.isAcknowledged());
}
}
|
本来应该是private RestHighLevelClient restHighLevelClient;这里为了简便,所以用Qualifier来限定client为restHighLevelClient;
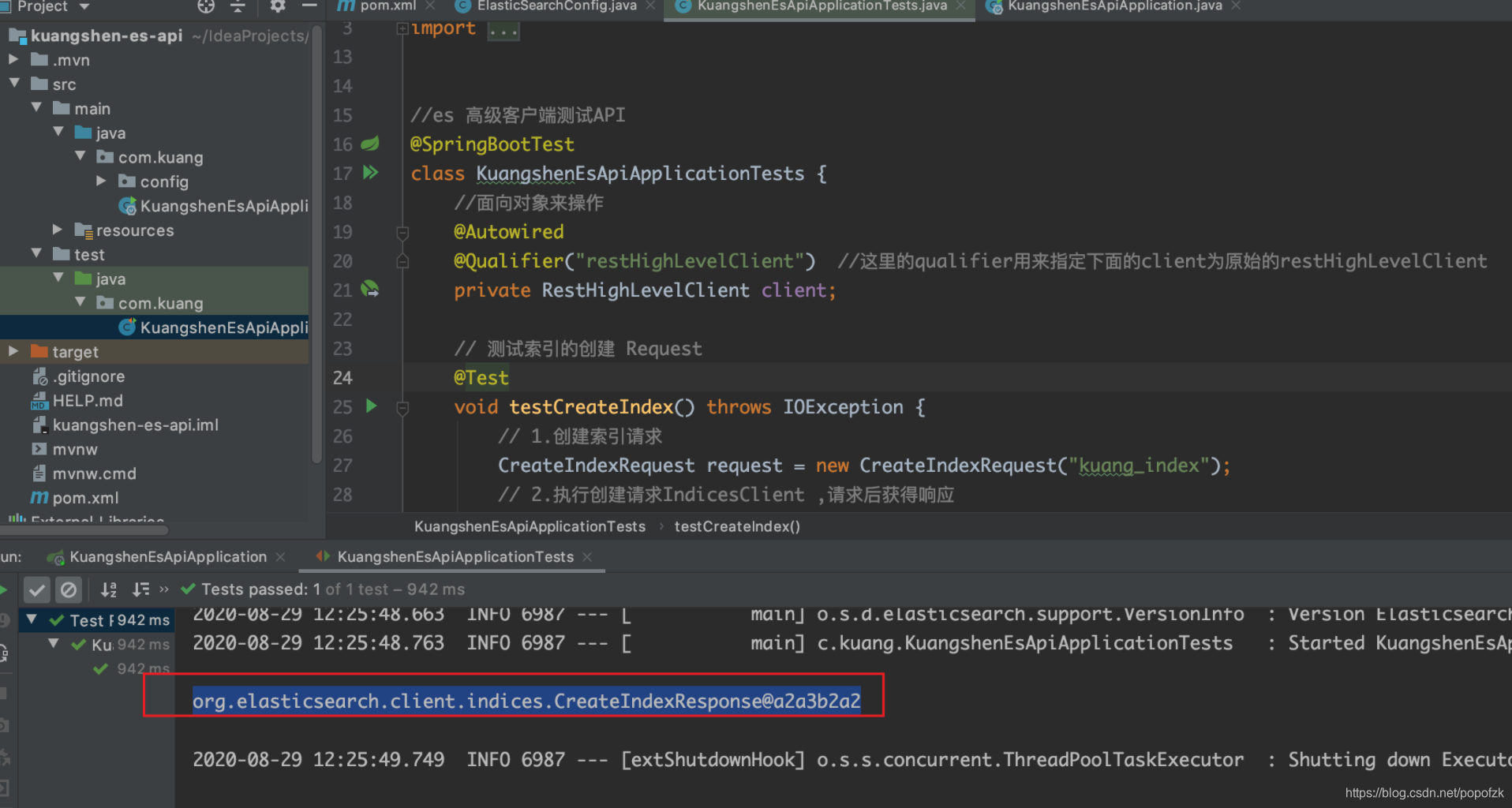

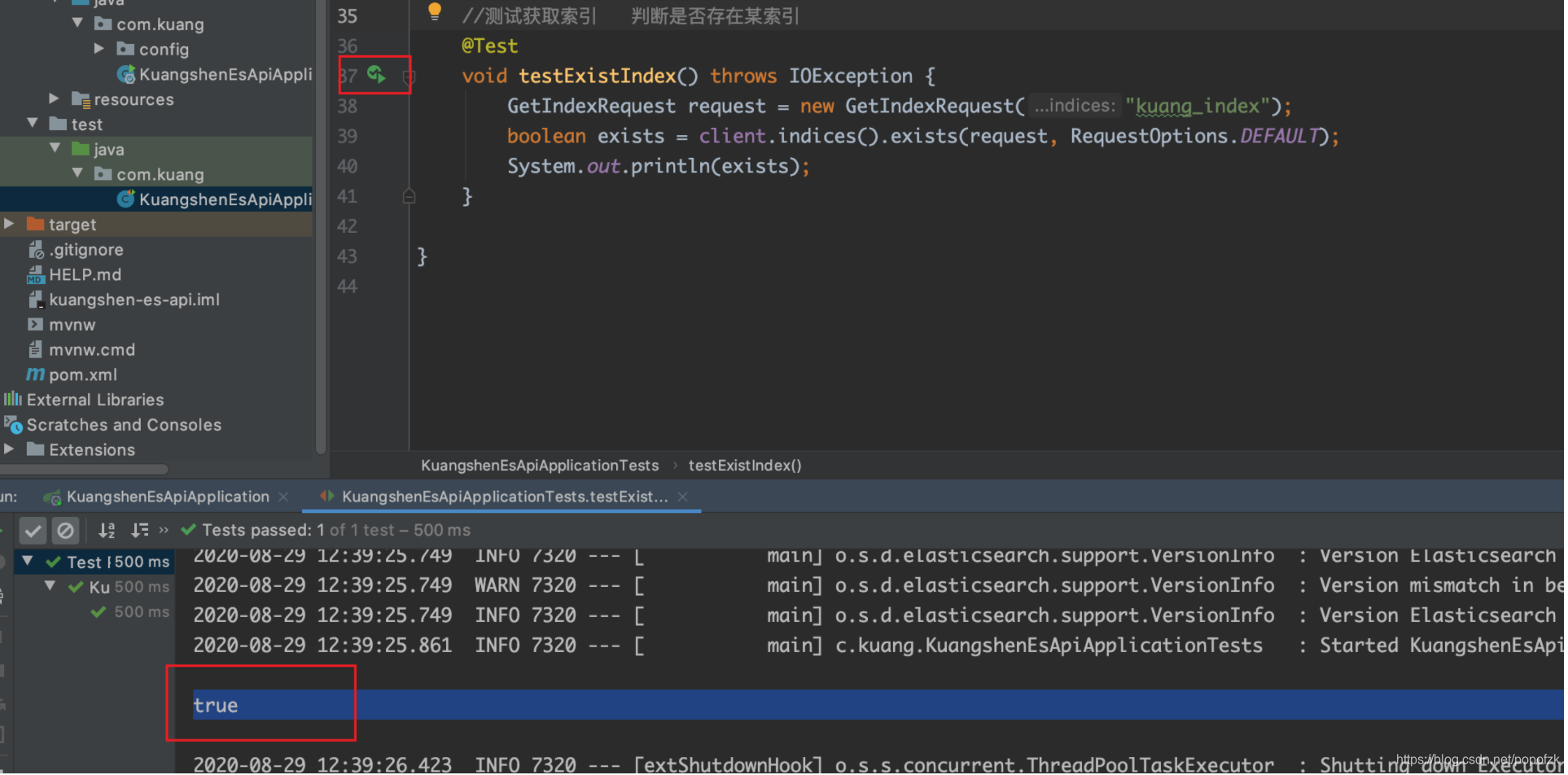
- 创建索引
- 判断索引是否存在
- 删除索引
- 创建文档
- crud文档
创建文档
新建一个pojo,放入User.java
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| package com.kuang.pojo;
import lombok.AllArgsConstructor;
import lombok.Data;
import lombok.NoArgsConstructor;
import org.springframework.stereotype.Component;
@Data
@AllArgsConstructor
@NoArgsConstructor
@Component
public class User {
private String name;
private int age;
}
|
由于要将我们的数据放入请求 json,故在pom中导入阿里巴巴fastjson
这里是将对象编写为Json,再放入es的request中
编写test类:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
| @Test
void testAddDocument(){
User user = new User("狂神说",3);
IndexRequest request = new IndexRequest("kuang_index");
request.id("1");
request.timeout(TimeValue.timeValueSeconds(1));
request.timeout("1s");
request.source(JSON.toJSONString(user), XContentType.JSON);
IndexResponse indexResponse = client.index(request, RequestOptions.DEFAULT);
System.out.println(indexResponse.toString());
System.out.println(indexResponse.status());
}
|

获取文档
1
2
3
4
5
6
7
8
|
@Test
void testGetDocument() throws IOException {
GetRequest getRequest = new GetRequest("kuang_index", "1");
GetResponse getResponse = client.get(getRequest, RequestOptions.DEFAULT);
System.out.println(getResponse.getSourceAsString());
System.out.println(getResponse);
}
|

更新文档信息
1
2
3
4
5
6
7
8
9
10
11
12
13
|
@Test
void testUpdateDocument() throws IOException {
UpdateRequest updateRequest = new UpdateRequest("kuang_index","1");
updateRequest.timeout("1s");
User user = new User("狂神说Java", 18);
updateRequest.doc(JSON.toJSONString(user),XContentType.JSON);
UpdateResponse updateResponse = client.update(updateRequest, RequestOptions.DEFAULT);
System.out.println(updateResponse.status());
}
|

删除文档信息
1
2
3
4
5
6
7
8
9
|
@Test
void testDeleteRequest() throws IOException {
DeleteRequest request = new DeleteRequest("kuang_index", "1");
request.timeout("1s");
DeleteResponse deleteResponse = client.delete(request, RequestOptions.DEFAULT);
System.out.println(deleteResponse.status());
}
|
批量插入
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
|
@Test
void testBulkRequest() throws IOException{
BulkRequest bulkRequest = new BulkRequest();
bulkRequest.timeout("10s");
ArrayList<User> userList = new ArrayList<>();
userList.add(new User("psz",11));
userList.add(new User("psz2",12));
userList.add(new User("psz3",13));
userList.add(new User("psz4",14));
userList.add(new User("psz5",15));
for (int i = 0; i < userList.size(); i++) {
bulkRequest.add(
new IndexRequest("kuang_index")
.id(""+(i+1))
.source(JSON.toJSONString(userList.get(i)),XContentType.JSON));
}
BulkResponse bulkResponse = client.bulk(bulkRequest, RequestOptions.DEFAULT);
System.out.println(bulkResponse.hasFailures());
}
|

查询
小技巧:
一般企业中,会把index名存在utils里面的ESconst.java文件中:
1
2
3
4
5
| package com.kuang.utils;
public class ESconst {
public static final String ES_INDEX = "kuang_index";
}
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
|
@Test
void testSearch() throws IOException {
SearchRequest searchRequest = new SearchRequest(ESconst.ES_INDEX);
SearchSourceBuilder sourceBuilder = new SearchSourceBuilder();
TermQueryBuilder termQueryBuilder = QueryBuilders.termQuery("name", "qinjiang1");
sourceBuilder.query(termQueryBuilder);
sourceBuilder.timeout(new TimeValue(60, TimeUnit.SECONDS));
searchRequest.source(sourceBuilder);
SearchResponse searchResponse = client.search(searchRequest, RequestOptions.DEFAULT);
System.out.println(JSON.toJSONString(searchResponse.getHits()));
System.out.println("--------------------------------------");
for (SearchHit documentFields : searchResponse.getHits().getHits()) {
System.out.println(documentFields.getSourceAsMap());
}
}
|





