
百万抽奖系统架构设计入门
前言从宏观架构层面去考虑一个抽奖系统的设计,在不涉及过多中间件的情况下,最朴素的想法其实就是一个抽奖服务器(tomcat 或者Springboot搭建)、一个通知服务器、MySQL数据库,可以完成用户抽奖到被通知是否抽到奖的过程。
V1:Base设计那么这个最简单的demo系统涉及到的问题就比较明显了:
单点问题:抽奖和通知服务器都是单点的,有单点风险,可以增加多个节点
负载均衡:如果增多节点,会涉及负载均衡问题(节点之间的访问规则,如果去降低服务器的访问压力),负载均衡可以用nginx,可以用轮询、一致性哈希、最近最少访问轮询算法
下面增加多个节点,并使用nginx实现负载均衡。
V2:考虑单点风险从而将V1版本的单点服务器进化成了集群,提高了高可用(a节点挂了,b节点还能访问),从而避免了单点风险。
V3:考虑流量大对于一个百万级、千万级的抽奖系统,流量必然非常大,如何进行考虑呢?当然,最暴力的方式就是无限的去横向扩展服务器(增大节点数,增大到十几万太服务器节点),但是这也不是无限制的,完全不现实,如何可以尽可能的用较少的硬件成本去解决问题呢?
流量大之限流
限流如果流量非常大 ...

负载均衡算法之一致性哈希环
前言现在有一个场景:一个客户端去访问服务端,只能一直访问一台机器,因为有一些用户数据就存在该服务器上面,如果访问其他服务器的话,这个用户数据就丢了,如何用算法来解决这个问题?
一致性哈希环算法base这里的环结构是我们想象的、抽象出来的,最朴素的想法,就是给一个请求,用哈希函数等操作去计算出它对应到的服务器位置,然后分配即可。客户端如何映射到哈希环上的节点呢?
比如有一个userId =1去请求:计算了哈希值后落在了P1与P4之间,哈希环处理规则就是找到比它大的最近的那个节点,这里的哈希环是一个有序环,依次递增:P1< P2< P3< P4,那么比userId =1大的最近的就是P1,那么就会分配给P1这个服务器。 在Java中有哪个数据结构是可以满足这个需求的呢?完成自动排序(比如一个数字进到集合中后,该结构能够将新来的和之前的集合元素进行排序,这里采用的是TreeMap)
变种:穿插虚拟节点分担请求压力思考一个问题:如果在某个高峰时间,所有的请求都打到了P1-P4这个区域,那么将会全部击中P1这台服务器,P1承受很大流量,可能导致宕机,同时其他服务器可能比较空闲, ...

初探负载均衡算法【随机、轮询、加权随机、加权轮询、平滑加权轮询】
简介负载平衡(Load balancing)是一种在多个计算机(网络、CPU、磁盘)之间均匀分配资源,以提高资源利用的技术。使用负载均衡可以最大化服务吞吐量,可能最小化响应时间,同时由于使用负载均衡时,会使用多个服务器节点代单点服务,也提高了服务的可用性。
负载均衡的实现可以软件可以硬件,硬件如大名鼎鼎的 F5 负载均衡设备,软件如 NGINX 中的负载均衡实现,又如 Springcloud Ribbon 组件中的负载均衡实现。本文主要从软件层面来说明其实现算法。
负载均衡算法主要分为以下6大类:
随机
轮询
加权随机
加权轮询
一致性哈希
平滑加权轮询
代码示例:先把三台服务器放在集合中去:
12345678910111213141516//服务器IPpublic class ServerIps { //不带权重的三台服务器,用List存储 public static final List<String> LIST = Arrays.asList( "A", "B", "C" ); ...

Redis缓存穿透 击穿 雪崩
缓存请求流程Redis缓存的雪崩、穿透、击穿属于日常工作中经常会遇到的经典问题,下面来一探究竟,他们的解决方案主要是:布隆过滤器、分布式锁(下次再写)这是一个简单的客户端、服务端请求Redis的流程图,简单来说就是当用户向服务端进行访问时,服务端如果需要向数据库请求数据时,先去缓存中看有没有,有则直接返回,没有才会再去数据库中查询返回,这是一个正常的缓存流程。
缓存雪崩比如这个某宝的场景,当双十一来临之日,用户的访问量是非常之大的,所以有很多的数据是放进Redis中缓存起来,对应了Redis的key,并且设置了缓存失效时间是三小时,当双十一期间,购物超过三小时之后,缓存同时在一瞬间全部都失效了,导致所有的请求全部打到了数据库上,造成数据库响应不及时而挂掉,这时候就没办法对外提供该服务了。简单来说:用户访问某宝,Redis中的key大面积失效,导致直接与数据库沟通,这种现象就叫缓存雪崩。解决方案:
设置失效时间,让他不要在同一时间失效,在设置缓存的时候,随机初始化失效时间,这样就不会让所有的缓存在同一时间全部失效,尽可能分散分布。
Redis一般都是集群部署,我们将热点key放到不同的 ...

布隆过滤器【1970年由布隆提出;Redis缓存穿透解决方案】
什么是布隆过滤器布隆过滤器(Bloom Filter),是1970年,由一个叫布隆的小伙子提出的,距今已经五十年了。
它实际上是一个很长的二进制向量和一系列随机映射函数,二进制大家应该都清楚,存储的数据不是0就是1,默认是0。
主要用于判断一个元素是否在一个集合中,0代表不存在某个数据,1代表存在某个数据。
布隆过滤器用途
解决Redis缓存穿透
举例:在爬虫时,对爬虫网址进行过滤,已经存在布隆中的网址,不再爬取。
举例:垃圾邮件过滤,对每一个发送邮件的地址进行判断是否在布隆的黑名单中,如果在就判断为垃圾邮件。
布隆过滤器原理存入过程布隆过滤器上面说了,就是一个二进制数据的集合。当一个数据加入这个集合时,经历如下洗礼(这里有缺点,下面会讲):
通过K个哈希函数计算该数据,返回K个计算出的hash值
这些K个hash值映射到对应的K个二进制的数组下标
将K个下标对应的二进制数据改成1。
例如,第一个哈希函数返回x,第二个第三个哈希函数返回y与z,那么: X、Y、Z对应的二进制改成1。
查询过程布隆过滤器主要作用就是查询一个数据,在不在这个二进制的集合中,查询过程如下:
通 ...

MySQL用了索引为什么还是查询很慢?查询速度和什么因素有关?
前言近几个月在华为实习的过程中,有个场景下取数,对于一个sn号的查询竟然长达几分钟的时间,批量查几十个sn时,则需要一二十分钟的sql查询时间,故专门对这个问题进行一些整理和思考。首先,这个数据库是存在HIVE上,经过和一些前辈交流后,了解到企业中的数据库主要分为两大种:OLTP(on-line transaction processing)事务型、OLAP(On-Line Analytical Processing)分析型。
OLTP是传统的关系型数据库的主要应用,主要是基本的、日常的事务处理,例如银行交易。
OLAP是数据仓库系统的主要应用,支持复杂的分析操作,侧重决策支持,并且提供直观易懂的查询结果。
那么,事务型数据库OLTP主要以小的事务以及小的查询为主,评估其系统的时候,一般看其每秒执行的Transaction以及Execute SQL的数量。在这样的系统中,单个数据库每秒处理的Transaction往往超过几百个,或者是几千个,Select 语句的执行量每秒几千甚至几万个。OLTP系统最容易出现瓶颈的地方就是CPU与磁盘子系统。
OLAP,也叫联机分析处理(Onl ...

初探MySQL 读已提交和可重复读级别下 MVCC并发版本控制实现原理
事务ACID回顾InnDB引擎下,具备事务功能,事务具备ACID(原子性、一致性、隔离性、持久性),一致性其实是目的,由原子性、隔离性和持久性共同来保证!原子性是由undo log来进行保证的(回滚的时候采用undo log),持久性由InnoDB的redo log、undo log、 binlog来保证,而隔离性指的是它有四个隔离级别,分别是:
读未提交
读提交
可重复读
串行化
其中我们用的比较多的是 读提交(RC) 和 可重复读(RR),下面来详细介绍一下他们是如何通过MVCC多版本并发控制实现的。
MVCC在MySQL InnoDB存储引擎下,RC、RR基于MVCC(多版本并发控制)进行并发事务控制
MVCC是基于”数据版本”对并发事务进行访问
下面举一个例子来说明实现原理:
现在有三个事务,事务id分别是 trx_id = 1、2、3、4;前面三个事务都对张三这个人做了name的更新并且提交,事务4就是在两个时间段去做了“读”操作,我们先来看在“读提交”的隔离级别下,事务4的两次读操作会读出什么结果呢?
如果是RC级别,那么 select1 = 张三,sel ...
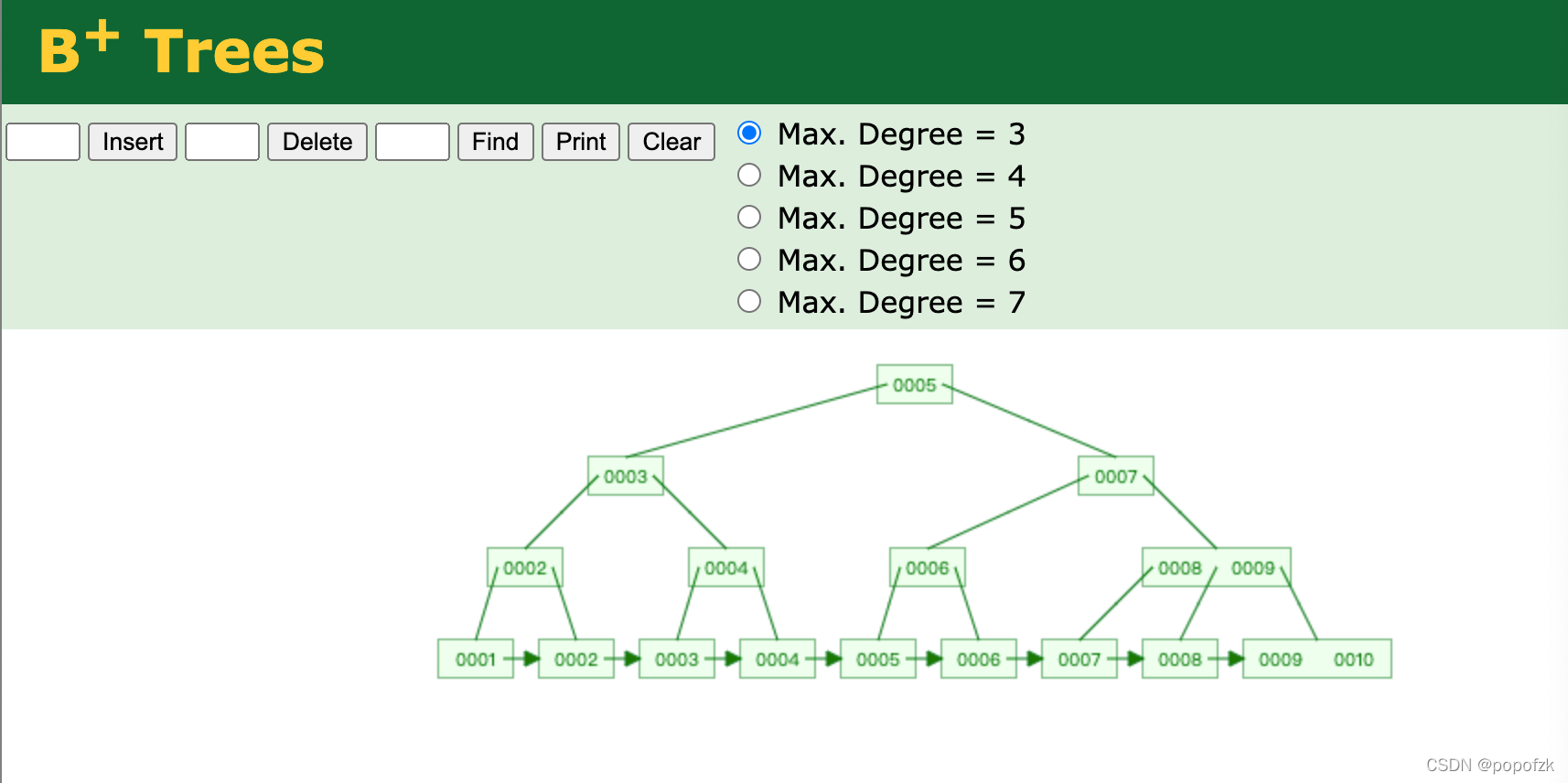
MySQL底层采用B+ tree的原因剖析【哈希、平衡二叉、B树为啥不行?】
MySQL索引底层采用B+ tree的原因哈希索引https://www.cs.usfca.edu/~galles/visualization/ClosedHash.html
通过 哈希 函数计算和类似取余运算,可以将元素插入到对应的bucket中,find的过程是o(1)时间复杂度,那find速度这么快,为啥Mysql底层不用呢?
因为Mysql的查询涉及大量的范围查询,Hash索引这个无序集合,是不支持范围查询的,再比如mysql的排序查询(order by),而哈希是无序的,也无法支持!就像我们的uuid是无序的,不可能用他来做主键。
平衡二叉树https://www.cs.usfca.edu/~galles/visualization/AVLtree.html
平衡二叉树的左右子树的高度差不会大于1。
无论怎么插,高度差都会维持,
随着树的高度增加,他的查询速度也会逐渐变慢,
比如这里找8,一次就找到了,但是找10找了三次。
还有一个致命缺点,如果我们去查5,通过三次定位找到了5,如果要找大于5的数据,就要从5这个节点往回查找,找到6,7,再回到更上一层的8,往下再9、10, ...
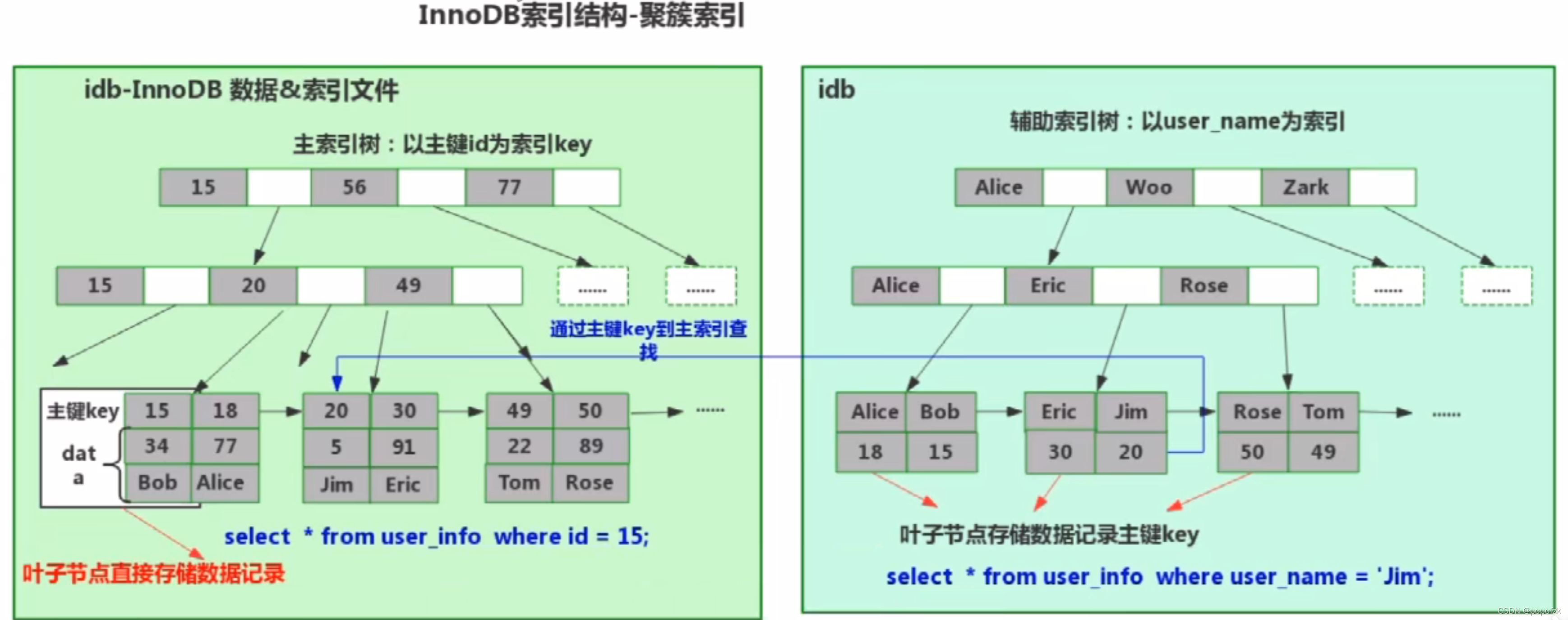
MySQL如何通过索引找到一条真实的数据?
MySQL如何通过索引找到一条真实的数据Mylsan和 InnoDB常见区别事务方面noDB支持事务, MyISAM不支持事务。这是 MySQL将默认存储引擎从 MyISAM变成 innoDB的重要原因之
外键方面nnoDB支持外键,而 MyISAM不支持。对一个包含外键的 innoDB表转为 MYISAM会失败。
索引层面innoDB是聚集(聚簇)索引, MyISAM是非聚集(非聚簇)索引。后面会重点讲解这两种索引的区别MyISAM支持 FULLTEXT类型的全文索引,innoDB不支持 FULLTEXT类型的全文索引,但是 innoDB可以使用 sphinx插件支持全文索引,并且效果更好。
锁粒度方面innoDB最小的锁粒度是行锁, MyISAM最小的锁粒度是表锁。一个更新语句会锁住整张表,导致其他查询和更新都会被阻塞,因此并发访问受限
这也是MySQL将默认存储引擎从MyISAM变成InnoDB的重要原因之一。
硬盘存储结构MyISAM在磁盘上存储成三个文件。第一个文件的名字以表的名字开始,扩展名指出文件类型。
frm文件存储表的定义
数据文件的扩展名为.MND( MYData ...

还不了解lambda?还再用迭代遍历操作集合?赶紧上Stream流!
函数式编程(Lambda && Stream)参考:《Java8实战》+《B站三更草堂》
以sort引入匿名内部类->lambda
我们常常用传入Comparator来完成排序行为的传入,这里我们传进去的实际上是如何排序这个行为,lambda实际上就是让我们尽可能的去关注这个行为本身,至于Comparator这个接口里面要覆盖重写的方法叫啥,我们其实没必要过多的关心,关注一下返回类型就够了。
12345678910public static void main(String[] args) { List<Integer> integers = Arrays.asList(1, 5, 2, 7, 10); Collections.sort(integers, new Comparator<Integer>() { @Override public int compare(Integer o1, Integer o2) { ...